Regressão Logística
Na ciência de dados e estatística, a regressão logística é um dos modelos de aprendizado supervisionado mais importantes e amplamente utilizados, especialmente quando o objetivo é prever uma variável categórica binária, como sim/não, verdadeiro/falso ou 0/1. Embora o nome inclua "regressão", este método não mede relações lineares entre variáveis numéricas, mas sim a probabilidade de um evento ocorrer com base em uma combinação de fatores. Sua popularidade se deve à simplicidade, interpretabilidade e robustez, sendo aplicável em diversas áreas como medicina, finanças, marketing e ciências sociais.
O que é regressão logística e como funciona
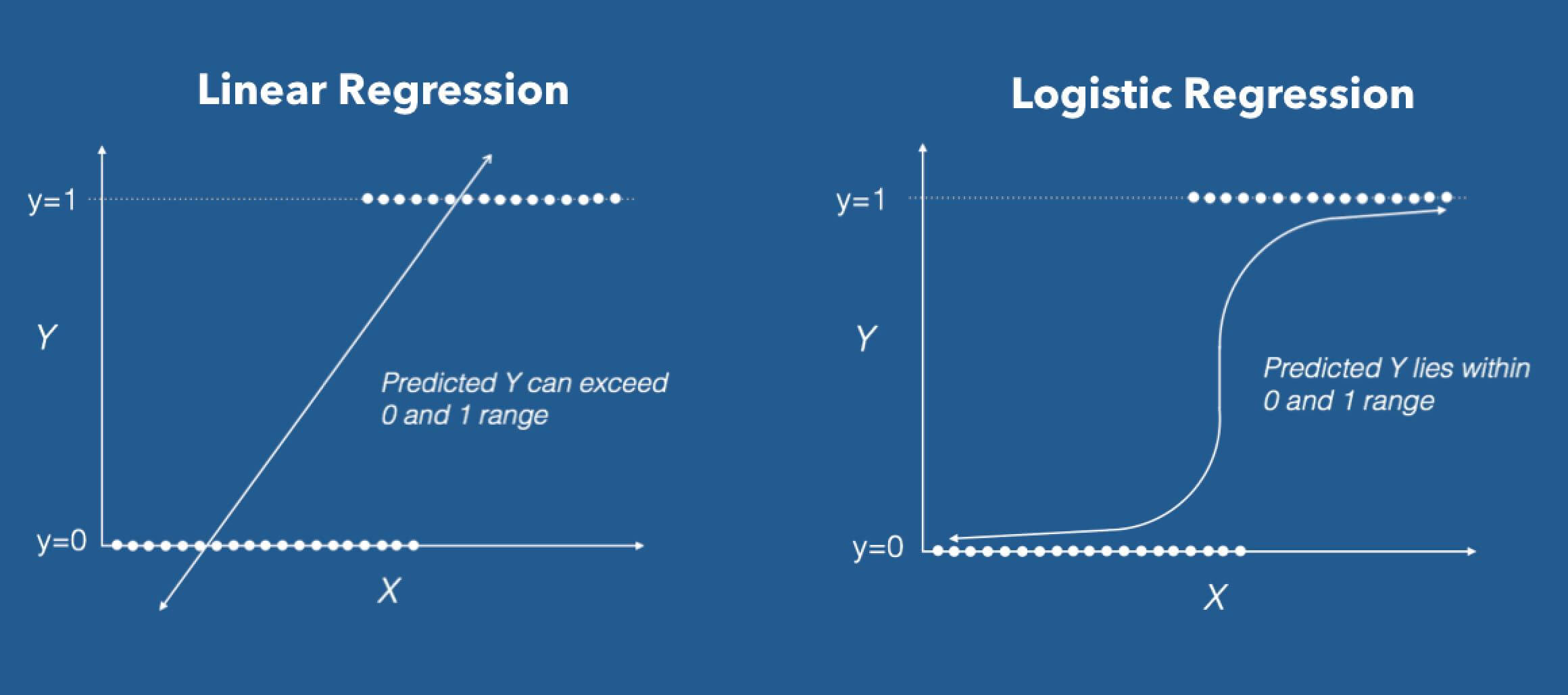
A regressão logística modela a probabilidade de uma observação pertencer a uma classe específica, utilizando a função logística, também conhecida como sigmoid, que transforma qualquer valor real em um número entre 0 e 1. Essa saída é interpretada como a probabilidade de ocorrência do evento de interesse, como um cliente cancelar um serviço ou um paciente apresentar uma determinada condição de saúde. O modelo combina de forma linear as variáveis preditoras com seus respectivos coeficientes, mas aplica a transformação sigmoid para garantir que a previsão esteja sempre dentro do intervalo probabilístico.
Matematicamente, a fórmula da regressão logística envolve o logaritmo da razão entre a probabilidade de sucesso e a probabilidade de falha, conhecido como logito. Este logaritmo é modelado como uma combinação linear das variáveis explicativas, permitindo que analistas quantifiquem o impacto de cada característica no resultado. Diferente da regressão linear, que pode produzir valores fora do intervalo [0,1], a regressão logística oferece previsões coerentes com a natureza probabilística de problemas de classificação binária.

Tipos de regressão logística
Existem basicamente três formatos da regressão logística, determinados pelo tipo de variável dependente que se deseja modelar. O primeiro é o modelo binário, utilizado quando a variável-alvo possui apenas duas categorias, como aprovação ou reprovação em um exame. É o formato mais comum e geralmente o mais direto de ser interpretado, pois responde a perguntas do tipo "qual é a chance de um evento ocorrer?"
O segundo tipo é a regressão logística multinomial, que é aplicada quando a variável dependente possui mais de duas categorias sem uma ordem intrínseca, como escolher entre diferentes marcas de um produto. Já a regressão logística ordinal é usada quando as categorias têm uma ordem natural, como baixo, médio e alto. Nesse caso, o modelo leva em consideração a estrutura classificatória, oferecendo estimativas mais precisas quando as suposições de ordem são válidas.
Quando usar regressão logística
A escolha da regressão logística faz sentido em situações onde o objetivo principal é classificar observações em categorias discretas, especialmente quando se busca um modelo simples e transparente. É indicado quando a variável dependente é categórica e as variáveis independentes podem ser tanto numéricas quanto categóricas, desde que as premissas do modelo sejam respeitadas. Além disso, a regressão logística é particularmente útil quando a interpretação dos fatores que influenciam a decisão é tão importante quanto a própria previsão.

Antes de aplicar o modelo, é fundamental validar pressupostos como a ausência de multicolinearidade entre as variáveis preditoras, a linearidade entre as variáveis independentes e o logito da variável dependente, bem como garantir que as observações sejam independentes entre si. Quando esses critérios são atendidos, a regressão logístrica proporciona não apenas boas taxas de acerto, mas também insights valiosos sobre a relação causa-efeito entre as características analisadas e o resultado.
Vantagens e limitações
Uma das principais vantagens da regressão logística é a sua eficiência computacional, exigindo menos recursos que modelos mais complexos, como redes neurais ou florestas aleatórias. Sua matemática relativamente simples facilita a compreensão dos coeficientes, que podem ser interpretados como o quanto a probabilidade do evento aumenta ou diminui com uma unidade de mudança na variável preditora. Além disso, o modelo oferece probabilidades naturalmente, o que é muito útil em contextos de tomada de decisão sob risco.
Porém, a regressão logística também apresenta limitações importantes. Ela assume que as relações entre as variáveis são lineares no espaço logito, o que nem sempre é verdade no mundo real. Além disso, é sensível a variáveis irrelevantes e pode sofrer com problemas de separabilidade quando as classes são facilmente distinguíveis, resultando em coeficientes extremos. Em problemas complexos com padrões não lineares intensos, modelos mais avançados geralmente superam seu desempenho, mas a regressão logística continua sendo uma excelente opção de partida e baseline em projetos de classificação.
Perguntas frequentes
Pode usar regressão logística para mais de duas categorias?
Sim, existem variantes como a regressão logística multinomial e ordinal que permitem modelar variáveis dependentes com mais de duas categorias, desde que respeitadas as particularidades de cada tipo.
Qual a diferença entre regressão linear e regressão logística?
A regressão linear prevê valores numéricos contínuos, enquanto a regressão logística é usada para prever probabilidades de eventos discretos, aplicando uma função sigmoid para limitar a saída entre 0 e 1.
É necessário normalizar as variáveis antes de usar regressão logística?
Embora não seja obrigatório, normalizar ou padronizar variáveis numéricas pode ajudar na convergência do algoritmo e na interpretação dos coeficientes, especialmente quando as escalas das variáveis são muito diferentes.

Como avaliar a qualidade de um modelo de regressão logística?
Utilize métricas como acurácia, precisão, recall, F1-score e a curva ROC-AUC, além de validação cruzada, para medir o desempenho e a capacidade de generalização do modelo em dados não vistos.
